This post explores automated decision-making systems in the context of the EU General Data Protection Regulation (GDPR). Recent discussions have focused on what exactly the GDPR requires of data controllers who are implementing automated decision-making systems. In particular, what information should be provided to those who are subject to automated decisions? I’ll outline the legal context and then present an example of what that might mean at a technical level, working through a very simple machine learning task in an imaginary credit lending scenario.
The legal context
In May next year, the GDPR will come into force in EU member states (including the UK). Part of the Regulation that has gained a fair amount of attention recently is Article 22, which sets out rights and obligations around the use of automated decision making. Article 22 gives individuals the right to object to decisions made about them purely on the basis of automated processing (where those decisions have significant / legal effects). Other provisions in the GDPR (in Articles 13,14, and 15) give data subjects the right to obtain information about the existence of an automated decision-making system, the ‘logic involved’ and its significance and envisaged consequences. Article 22 is an updated version of Article 15 in the old Data Protection Directive. Member states implemented the Directive into domestic law around a couple of decades ago, but the rights in Article 15 of the Directive have barely been exercised. To put it bluntly, no one really has a grip on what it meant in practice, and we’re now in a similar situation with the new regulation.
In early proposals for the GDPR, the new Article 22 (Article 20 in earlier versions) looked like it might be a powerful new right providing greater transparency in the age of big data profiling and algorithmic decision-making. However, the final version of the text significantly watered it down, to the extent that it is arguably weaker in some respects than the previous Article 15. One of the significant ambiguities is around whether Articles 13, 14, 15, or 22 give individuals a ‘right to an explanation’, that is, an ex post explanation of why a particular automated decision was made about them.
Explaining automated decision-making
The notion of a ‘right to an explanation’ for an automated decision was popularised in a paper which garnered a lot of media attention in summer of last year. However, as Sandra Wachter and colleagues argue in a recent paper, the final text carefully avoids mentioning such a right in the operative provisions. Instead, the GDPR only gives the subjects of automated decisions the right to obtain what Wachter et al describe as an ex ante ‘explanation of system functionality’. Under Articles 15 (1) h, and 14 (2) g, data controllers must provide ‘meaningful information about the logic involved, as well as the significance and the envisaged consequences of such processing’ to the data subject. But neither of these provisions amount to an ex post explanation for a particular decision that has been made. The only suggestion of such a right appears in a Recital (71), which says appropriate safeguards should include the ability of data subjects ‘to obtain an explanation of the decision reached after such assessment’.
Since Recitals are not operative provisions and therefore not binding, this suggests that there is no ex post ‘right to explanation’ for specific decisions in the GDPR. It is conceivable that such a right becomes established by the court at a later date, especially if it were to pay close attention to Recital 71. It is also possible that member state DPAs, and the new European Data Protection Board in its harmonisation role, interpret Article 22 in this way, and advise data controllers accordingly. But until then, it looks like data controllers will not be required to provide explanations for specific automated decisions.
Having followed discussions about this aspect of the GDPR since the first proposal text was released in 2012, one of the difficulties has been a lack of specific and detailed examples of how these provisions are supposed to operate in practice. This makes it hard to get a grip on the supposed distinction between a ‘right to explanation of a decision’ and a mere ‘right to an explanation of system functionality’.
If I’m entitled as a data subject to an explanation of a system’s ‘functionality’, and its ‘likely effects’ on me, that could mean a lot of things. It could be very general or quite detailed and specific. At a certain level of generality, such an explanation could be completely uninformative (e.g. ‘based on previous data the model will make a prediction or classification, which will be used to make a decision’). On the other hand, if the system were to be characterised in a detailed way, showing how particular outputs relate to particular inputs (e.g. ‘applicants with existing debts are 3x less likely to be offered credit’), it might be possible for me to anticipate the likely outcome of a decision applied to me. But without looking at specific contexts, system implementations, and feasible transparency measures, it’s difficult to interpret which of these might be feasibly required by the GDPR.
A practical example: automated credit decisions
Even if legal scholars and data protection officers did have a clear idea about what the GDPR requires in the case automated decision making systems, it’s another matter for that to be implemented at a technical level in practice. In that spirit, let’s work through a specific case in which a data controller might attempt to implement an automated decision-making system.
Lots of different things could be considered as automated decision-making systems, but the ones that are getting a lot of attention these days are systems based on models trained on historical data using machine learning algorithms, whose outputs will be used to make decisions. To illustrate the technology, I’m going to explain how one might build a very simple system using real data (note: this is not intended to be an example of ‘proper’ data science; I’m deliberately going to miss out some important parts of the process, such as evaluation, in order to make it simpler).
Imagine a bank wants to implement an automated system to determine whether or not an individual should be granted credit. The bank takes a bunch of data from previous customers, such as their age, whether or not they have children, and the number of days they have had a negative balance (in reality, they’d probably use many more features, but let’s stick with these three for simplicity). Each customer has been labelled as a ‘good’ or ‘bad’ credit risk. The bank then wants to use a machine learning algorithm to train a model on this existing data to classify new customers as ‘good’ or ‘bad’. Good customers will be automatically granted credit, and bad customers will be automatically denied.
German credit dataset
Luckily for our purposes, a real dataset like this exists from a German bank, shared by Professor Hans Hofman from Hamburg University in 1994. Each row represents a previous customer, with each column representing an attribute, such as age or employment status, and a final column in which the customer’s credit risk has been labelled (either 1 for ‘Good’, or 2 for ‘Bad’).
For example, the 1,000th customer in the dataset has the following attributes:
‘A12 45 A34 A41 4576 A62 A71 3 A93 A101 4 A123 27 A143 A152 1 A173 1 A191 A201 1’
The ‘A41’ attribute in the 4th column indicates that this customer is requesting the credit in order to purchase a used car (a full description of the attribute codes can be found here http://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)). The final column represents the classification of this customer’s credit risk (in this case 1 = ‘good’).
Building a model
Let’s imagine I’m a data scientist at the bank and I want to be able to predict the target variable (risk score of ‘good’ or ‘bad’) using the attributes. I’m going to use Python, including the pandas module to wrangle the underlying CSV file into an appropriate format (a ‘data frame’), and the scikit-learn module to do the classification.
import pandas as pd
from sklearn import tree
Next, I’ll load in the german credit dataset, including the column headings (remember, for simplicity we’re only going to look at three features – how long they’ve been in negative balance, their age and the number of dependents):
features = ["duration", "age", "num_depend", "risk"]
df = pd.read_csv("../Downloads/german.data", sep=" ", header=0, names=features)
The target variable, the thing we want to predict, is ‘risk’ (where 1 = ‘good’ and 2 = ‘bad’). Let’s label the target variable y and the features X.
y = df[["risk"]]
X = df[features]
Now I’ll apply a basic Decision Tree classifier to this data. This algorithm partitions the data points (i.e. the customers) into smaller and smaller groups according to differences in the values of their attributes which relate to their classification (i.e. ‘people over 30’, ‘people without dependents’). This is by no means the most sophisticated technique for this task, but it is simple enough for our purposes. We end up with a model which can take as input any customer with the relevant set of attributes and return a classification of that customer as a good or bad credit risk.
The bank can then use this model to automatically make a decision about whether or not to grant or deny credit to the customer. Imagine a customer, Alice, makes an application for credit, and provides the following attributes;
Alice = {'duration' : 10, 'age' : 40, 'num_depend' : 1}
We then use our model to classify Alice:
# convert the python Dict into a pandas dataframe
Alice = pd.Series(Alice)
# reshape the values since sklearn doesn't accept 1d arrays
Alice = Alice.values.reshape(1, -1)
print clf.predict(Alice)
The output of our model for Alice is 2 (i.e. ‘bad’), so Alice is not granted the credit.
Logic, significance and consequences of automated decision taking
How could the bank provide Alice with ‘meaningful information about the logic involved, as well as the significance and the envisaged consequences of such processing’?
One proposal might be to provide Alice with a representation of the decision tree model that resulted from the training. This is what that looks like:
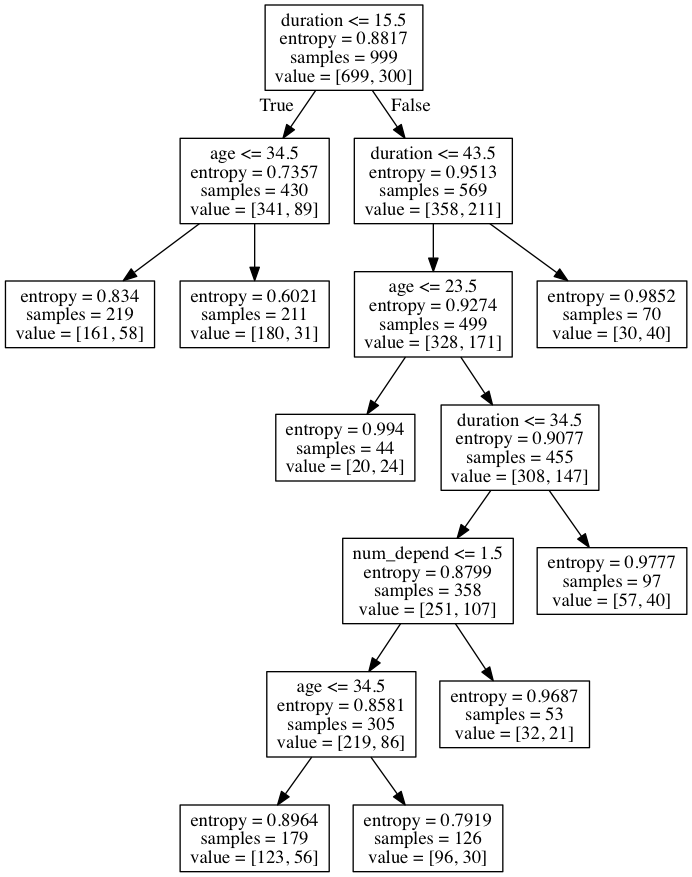
Reading from the top-down, each fork in the tree shows the criteria for placing an individual in one of two sides of the fork.
If Alice knows which personal attributes the bank knows about her (i.e. 40 years old, 1 dependent, 20 days in negative balance), she could potentially use this decision tree to work out whether or not this system would decide that she was a good credit risk. Reading from the top: the first fork asks whether the individual has 15.5 days or less in negative balance; since Alice has 20 days in negative balance, she is placed in the right hand category. The next fork asks whether the Alice has 43.5 days or less in negative balance, which she does. The next fork asks whether Alice is 23.5 years old or less, which she isn’t. The final fork on this branch asks if Alice has been in negative balance for 34.5 days or more, which she hasn’t, and at this point the model concludes that Alice is a bad credit risk.
While it’s possible for Alice to follow the logic of this decision tree, it might not provide a particularly intuitive or satisfactory explanation to Alice as to why the model gives the outputs it does. But it does at least give Alice some warning about the logic and the effects of this model.
Another way that the bank might provide Alice with information ‘meaningful information about the logic involved, as well as the significance and the envisaged consequences of such processing’ would be to allow Alice to try out what decisions the model would recommend based on a variety of different values for the attributes it considers. For instance, what if Alice was older, or younger? Would she receive a different decision?
The bank could show Alice the age threshold at which she would be considered a good or bad credit risk. If we begin with age = 40, we find that Alice is classified as a bad credit risk. The same is true for Alice at 41, 42, and 43. However, at age 44, Alice’s credit risk classification would tip over from bad to good. That small exercise in experimentation may give Alice an intuitive sense of at least one aspect of the logic of the decision-making system and its envisaged effects. We could do something similar with the other attributes – what if Alice had only had a negative balance for 10 days? What if Alice had more or less children?
If this kind of interactive, exploratory analysis were made available to Alice before she applied for credit, it might help her to decide whether or not she felt OK about this kind of automated-decision making system. It might help her decide whether she wants to object to it, as Article 22 entitles her to do. Rather than being presented in dry mathematical terms, the relationships between these variables and the target variable could be presented in colloquial and user-friendly ways; Alice could be told ‘you’re 4 years too young’ and ‘you’ve been in the red for too long’ to be offered credit.
At a later date, the data on which this model is trained might change, and thus the resulting model might give a different answer for Alice. But it is still possible to take a snapshot of the model at a particular time and, on that basis, provide potentially meaningful interfaces through which Alice could understand the logic, significance and effects of the system on her ability to gain credit.
Explanation: unknown
The point of this exercise is to put the abstract discussions surrounding the GDPR’s provisions on automated decision making into a specific context. If data controllers were to provide dynamic, exploratory systems which allow data subjects to explore the relationships between inputs and outputs, they may actually be functionally equivalent to an ex post explanation for a particular decision. From this perspective, the supposed distinction between an ex ante ‘explanation of system functionality’ and an ex post ‘explanation of a specific decision’ becomes less important. What’s important is that Alice can explore the logic and determine the likely effects of the automated decision-making system given her personal circumstances.
Some important questions remain. It’s easy enough, with a simple, low-dimensional model, to explore the relationships between certain features and the target variable. But it’s not clear how these relationships can be meaningfully presented to the data subject, especially for the more complex models that arise from other machine learning methods. And we know very little about how those who are subject to such automated decisions would judge their fairness, and what grounds they might have for objecting to them. Might Alice reject the putative relationship between a particular feature and the target variable? Might she object to the sampling techniques (in this case, Alice might quite reasonably argue that the attributes of German bank customers in 1994 have little bearing on her as a non-German credit applicant in 2017)? Perhaps Alice would reject the thresholds at which applicants are judged as ‘good’ or ‘bad’?
I hope this simplistic, but specific and somewhat realistic example can serve as a starting point for focused discussion on the options for usable, human-centered transparency around automated decision-making. This is a significant challenge which will require more research at the intersection of machine learning, law and human-computer interaction. While there has been some promising work on transparent / interpretable machine learning in recent years (e.g. ‘Quantitative Input Influence‘ and LIME), relatively little research has focused on the human factors of these systems. We know very little about how people might interpret and evaluate these forms of transparency, and how that might be affected by their circumstances and relative position in the context in which the decision is made.
These questions are important to explore if we want to create automated decision-making systems which adhere not just to the letter of data protection law, but also its spirit. The duty to provide information on the logic, significance and effects of algorithmic decision-making will mean very little, if it doesn’t provide data subjects with the ability to make an informed and reasonable decision about whether to subject themselves to such decisions.










